-

Property Intel Platform Review: Property Data Features, Analytics, and Alternatives
Buying, selling, or studying property can feel like detective work. You need clues. Prices.…
-
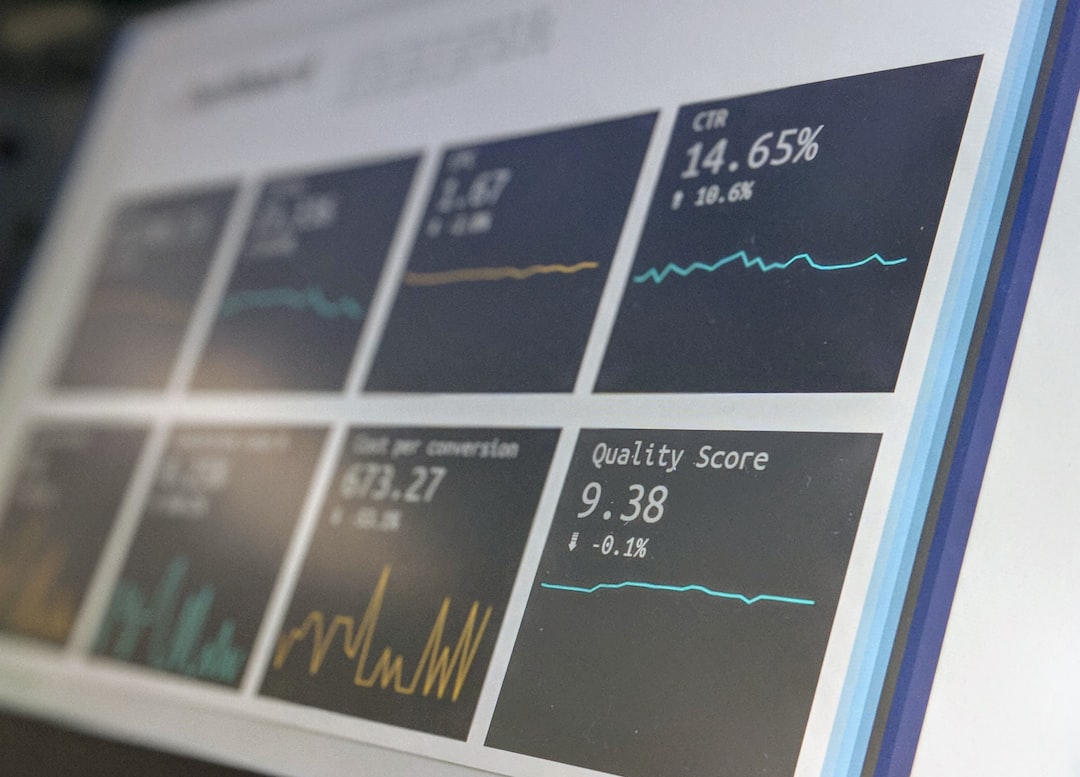
Xbert Company Overview: Customers, Growth, and Product Evolution from 2020 to 2026
Xbert has developed from a specialist accounting intelligence platform into a broader automation and…
-
Split Rent Payments: Best Apps and Services Compared
Sharing a home can make rent more affordable, but it also creates one recurring…
Business
-

What Is Cryptochain and How Does It Work?
Cryptochain refers to a digital record system in which data is grouped, verified, and…
Most Recent
Spotlight
-

Is the Fortnite Festival Pass Worth It? Review
Fortnite Festival has turned Fortnite into more than a battle royale hub; it is…
-

Why Are Video Editor Vacancies Increasing in the Digital Content Industry?
The demand for video editors is rising because digital content has become a core…
-

Fortnite Unblocked: How to Play at School Safely
Fortnite is more than a game for many students: it is a social space,…
The Latest
-
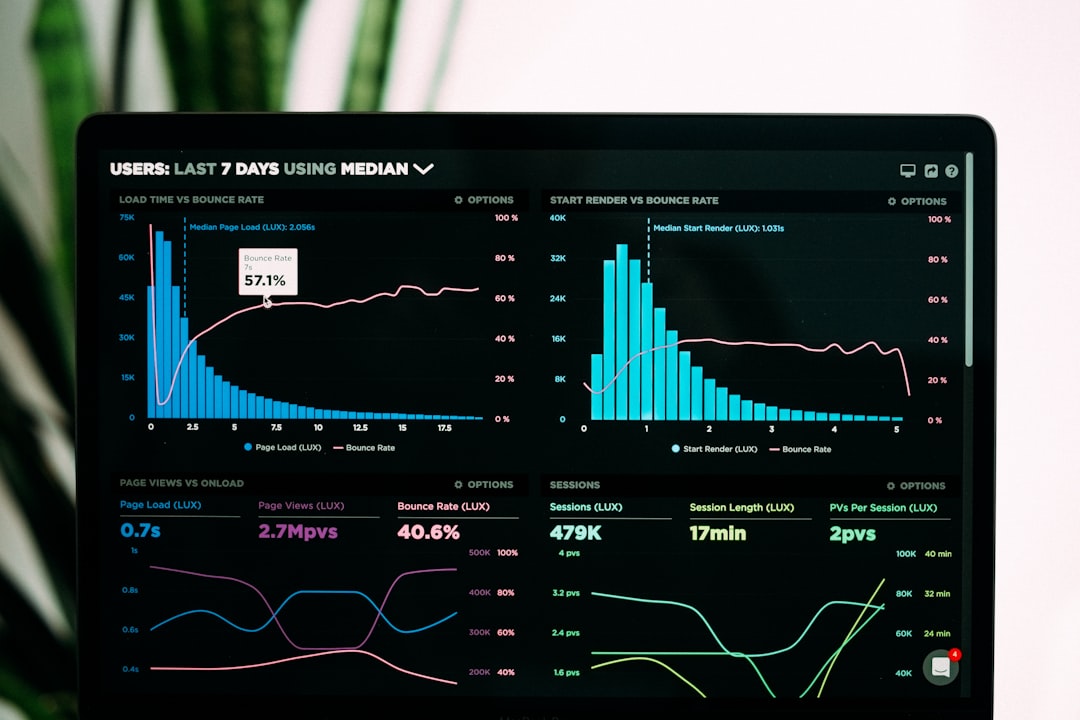
INSI Platform Overview: Features, Business Use Cases, and Pricing
INSI Platform is commonly discussed as a business software environment for organizations that need better visibility, workflow coordination, data monitoring, and operational reporting from one central system. Instead of treating…
-
Property Intel Platform Review: Property Data Features, Analytics, and Alternatives
Buying, selling, or studying property can feel like detective work. You need clues. Prices. Owners. Sales history. Rent trends. Local demand. A property intelligence platform puts those clues in one…
-
Xbert Company Overview: Customers, Growth, and Product Evolution from 2020 to 2026
Xbert has developed from a specialist accounting intelligence platform into a broader automation and workflow layer for accountants, bookkeepers, and small to mid-sized businesses. From 2020 to 2026, the company’s…
-
Split Rent Payments: Best Apps and Services Compared
Sharing a home can make rent more affordable, but it also creates one recurring financial challenge: collecting everyone’s share on time and proving it was paid. Split rent payment apps…
-

Best Financing Options for Home Fitness Equipment
Building a home gym can be a practical investment, especially if it replaces monthly gym fees, travel time, and unused memberships. However, quality fitness equipment can be expensive: a treadmill,…
-
NordicTrack Financing vs Affirm: Which Is Better?
Buying a NordicTrack treadmill, bike, rower, or elliptical can feel exciting. Then the price tag taps you on the shoulder and says, “Hello, remember me?” That is where financing comes…